This catches my eyes when I browse through CMUSphinx’s blog. That generally decides how the project will go.
http://cmusphinx.sourceforge.net/2010/03/development-meeting-notes/#more-157
Looks like resources is still an issue……
This catches my eyes when I browse through CMUSphinx’s blog. That generally decides how the project will go.
http://cmusphinx.sourceforge.net/2010/03/development-meeting-notes/#more-157
Looks like resources is still an issue……
Modern speech recognition software are complicated piece of software. To understand it, you need to have some basic understanding of the principle of speech recognition, as well as some ideas on the programming language being used.
By now, you may hear a lot of people say they know about a speech recognizer. And by now, you probably realize that most of these people have absolutely no ideas what’s going on inside a recognizer. So if you are reading this blog message, you are probably telling yourself, “I might want to trace the codebase of some recognizers’ code.” Be it Sphinx, HTK, Julius, Kaldi or whatever codebase you are looking at.
For the above toolkits, I will say I only know in detail about Sphinx, probably a little bit about HTK’s HVite. But I won’t say the same for others. In fact, even in Sphinx, I only know intimately about Sphinx 3/SphinxTrain/sphinxbase triplet. So just like you, I hope to learn more.
So here it begs the question: how would you trace a speech recognition toolkit codebase? If you think it is easy, probably because you worked in speech recognition for a while and you probably shouldn’t read this post.
Let’s just use sphinx as an example, there are hundreds of files in each component of Sphinx. So where should you start? A blunt approach would be reading each of the file one by one. That’s not a smart the way. So here is a suggestion for you : focus on the following four things,
This is another baby step on how one can learn about Sphinx 4. As I mentioned in the previous post, it is nicer to use an IDE when you use Java code. Since I have some exposure in Eclipse, I choose it as an example on how to setup a Sphinx 4 build.
Before I go on there were many posts, written by others, discuss the procedure. You may take a look of them as well.
Install JSAPI
I tried the install of both Windows Vista and Linux. In windows, go to
> jsapi.exe
Then accept the license.
In Linux, in the same directory. do
> sh jsapi.sh
One common problem for Linux here: you need to install uudecode if you want to install jsapi. In that case, try to install sharutil. On Ubuntu, it works for me when I do
> apt-get install sharutil
At this point you should see your directory should have a file named jsapi.jar
Incorporate the proper libraries
This is another part which took me a while. Before you go on to configure your path, you need to do one more step to make to configure libraries. In Eclipse, right click you Sphinx4/lib directory and choose Refresh first. This will make jsapi.jar appears your Package Explorer. It should look like this:
 |
| When JSAPI.jar is properly installed |
Then, you can change the build path, go to your project again, right click and choose Build Path -> Configure Build, Libraries, choose Add Jar, then add the libraries you need.
Now…. wait, what are the jar files we need again?
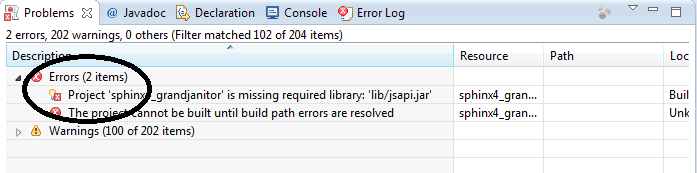
Yeah, so this is another place which can cause confusions. In fact, because Sphinx has expanded its code from time to time, so the answer of which jar files to add depends. As of Dec 28, 2012, you should add
This list will likely to grow in future. I am also pretty sure you might need to do different things if you want to compile in a different setting or write your own code.
Do the build
In modern Eclipse, building should be automatic, what you should see should be 0 errors but many warnings. I generally don’t approve of warnings but as a developer, it’s pretty tough to eliminate them all.
I considered GIT as a great improvement over CVS and SVN. SVN is okay if the codebase is not too large because SVN server sometimes get into lockup mode.
These are two great articles by James Hague on text processing vs visual programming.
The Unix Philosophy and a Fear of Pixels
Living inside your own Black Box
His main point is visual programming is often dismissed because it is way more difficult than text processing. It is a little bit like a lot of “stupid” things in the world such as Windows programming. They are actually quite tough to do well.
On speech processing, I guess it is appropriate to think sound programming is tougher than text processing as well. You may even think in speech processing, no one come up with a generic “Sound User Interface” IDE yet.
Arthur
If you track news of CMUSphinx, you may notice that the Sourceforge guys start to distribute data through BitTorrent (link).
That’s a great move. One of the issues in ASR is the lack of machine power in training. To make a blunt example, it’s possible to squeeze extra performance by searching for the best training parameters. Not to say a lot of modern training techniques take some time to run.
I do recommend all of your help the effort. Again, me not involved at all, just feel that it is a great cause.
Of course, things in ASR are never easy so I want to give two subtle points about the whole distributed approach of training.
First question you may ask, now does that mean, ASR can be like project such as SETI, which would automatically improve over the years? Not yet, ASR still has its unique challenge.
The major part I would see is how we can incrementally increase phonetically-balanced transcribed audio. Note that it is not just audio, but transcribed audio. Meaning: someone needs to go to listen to the audio, spending 5-10 times real time to write down what the audio really say word-by-word. All these transcriptions need to clean up and in a certain format.
This is what Voxforge tries to achieve and it’s not a small undertaking. Of course, comparing to the speed of the industry development, the progress is still too slow. The last time I heard, Google was training their acoustic model with 38000 hours of data. A WSJ corpus is a toy task compared to it.
Now, thinking in this way, let’s say if we want to build the best recognizer through open source, what is the bottleneck? I bet the answer doesn’t lie on machine power, whether we have enough transcribed data would be the key. So that’s something to ponder about.
(Added Dec 27, 2012, on the part of initial amount of data, Nickolay corrected me saying that amount of data from Sphinx is already in terms of 10000 hours. That includes “librivox recordings, transcribed podcasts, subtitled videos, real-life call recordings, voicemail messages”.
So it does sound like Sphinx has the amount of data which rivals commercial companies. I am very interested to see how we can train an acoustic model with that amount of data.)
decathect, stridulant
You can probably say, “He decathect from Mary by making a stridulant voice all the time.”
Arthur
As I update this blog more frequently, I noticed more and more people are directed to here. Naturally, there are many questions about some work in my past. For example, “Are you still answering questions in CMUSphinx forum?” and generally requests to have certain tutorial. So I guess it is time to clarify my current position and what I plan to do in future.
That’s another baby step but I guess Eclipse installation is much less painful these days.
When I used Eclipse back in 2008, it was rather difficult to download and install. Part of the reason is that the software house I worked with didn’t have a strong culture of documentation.
Downloading Eclipse Juno for Java Developer was pretty easy. My next step is to incorporate Sphinx 4 directory and do a compilation.
Arthur