This is another baby step on how one can learn about Sphinx 4. As I mentioned in the previous post, it is nicer to use an IDE when you use Java code. Since I have some exposure in Eclipse, I choose it as an example on how to setup a Sphinx 4 build.
Before I go on there were many posts, written by others, discuss the procedure. You may take a look of them as well.
You will also need to know how to install JSAPI (
link). It is crucial to get the compilation right.
Eclipse as a Development Environment
If you never use Eclipse before, it is a little bit like a more versatile version of Emacs. It’s major use is on Java but lately there are more and more people use it as IDE for C/C++ as well. Not to say there are more different development packages for different programming languages.
If you come from background such as emacs/vi development, one thing you need to know is that shortcuts are quite different from your current platform. That takes some time to adapt to but generally I think the advantage worth the cost.
Another thing you might want to be mentally prepare, Eclipse’s Java compilation doesn’t generate build log. Instead it will generate a list of errors in compilation. They are basically equivalent thing. Though, if you are used to Visual C++ type of IDE with an error log, you won’t get what you want.
To me, those are minor nuisances, using Eclipse to browse code has the extra advantage of readily-made documentation as well as a flatten structure. Those features will save you many keystrokes if compared to using vanilla emacs.
In my description, I am using Eclipse Juno. Hopefully it won’t change too much by the time you are compiling the code. Of course, if there is popular demand, I might write another post which describe later version of Eclipse as well.
The compilation in High Level
Building Sphinx 4 essentially means the following four tasks:
- Downloading Sphinx4 source code
- Install JSAPI.
- Incorporate the proper libraries.
- Do the build.
In my case, I slightly stumbled on 1, naturally, just like you, I was thinking “well, why JSAPI something separate from the codebase?” Of course, if you worked in Java before, there are many projects required you to build with external codebase. So I don’t think too bad.
So let me go through the procedure of the build.
Downloading Sphinx4 source code from Subclipse
- A plain simple svn command is fine, downloading the tarball will give you a more stable version. I will suggest a more attractive option is to use SVN module of Eclipse, subclipse. To do that, you may want to follow “Downloading Subclipse” from Setting up Development Environment . (Notice that there was a typo in the post should be “tigris” instead “trigris” on the location field.)
- Once you finished checking out Subclipse. Start a new Project
- New -> Project -> SVN -> Checkout Projects from SVN
- Choose “Create a New Repository Location”
- Remember to only download trunk/sphinx4 (Note: there are many branches and location, for starter, you will be interested how the trunk look like.)
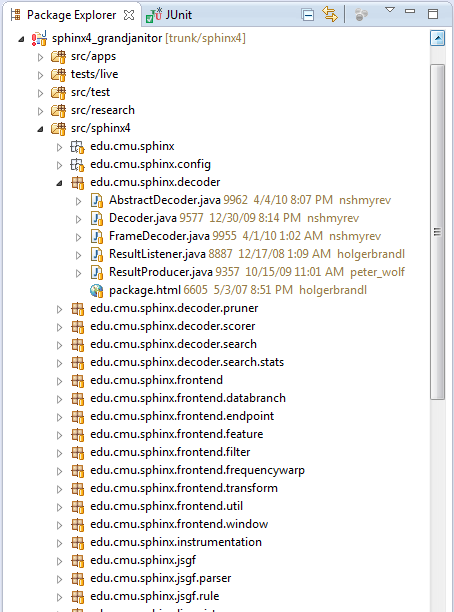
Once you check out the code, in your Package Explorer (Alt-Shift-Q -> P) will look like this.
Package Explorer View after code is check out from SVN
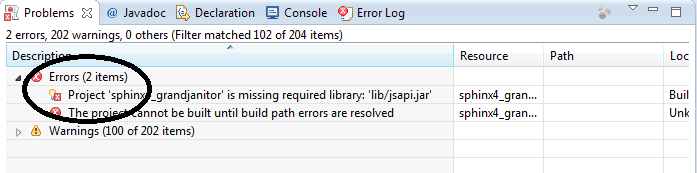
Now you might notice that there is a red question mark besides the sphinx4 project (I named it “sphinx4_grandjanitor” but you can name it whatever you want.) You might also notice that in your Problem screen, there are 2 errors :
Now this is really because lib/jsapi.jar wasn’t installed correctly. So the next step is to install jsapi.jar
Install JSAPI
I tried the install of both Windows Vista and Linux. In windows, go to sphinx4lib and type
> jsapi.exe
Then accept the license.
In Linux, in the same directory. do
> sh jsapi.sh
One common problem for Linux here: you need to install uudecode if you want to install jsapi. In that case, try to install sharutil. On Ubuntu, it works for me when I do
> apt-get install sharutil
At this point you should see your directory should have a file named jsapi.jar
Incorporate the proper libraries
This is another part which took me a while. Before you go on to configure your path, you need to do one more step to make to configure libraries. In Eclipse, right click you Sphinx4/lib directory and choose Refresh first. This will make jsapi.jar appears your Package Explorer. It should look like this:
 |
| When JSAPI.jar is properly installed |
Then, you can change the build path, go to your project again, right click and choose Build Path -> Configure Build, Libraries, choose Add Jar, then add the libraries you need.
Now…. wait, what are the jar files we need again?
Yeah, so this is another place which can cause confusions. In fact, because Sphinx has expanded its code from time to time, so the answer of which jar files to add depends. As of Dec 28, 2012, you should add
This list will likely to grow in future. I am also pretty sure you might need to do different things if you want to compile in a different setting or write your own code.
Do the build
In modern Eclipse, building should be automatic, what you should see should be 0 errors but many warnings. I generally don’t approve of warnings but as a developer, it’s pretty tough to eliminate them all.
Conclusion
There you have it, a little guide on Sphinx 4 compilation with Eclipse. Notice that this guide may or may not fit your purpose because I focus on downloading the code from Subclipse. Doing a Link Source should do the trick if you want to incorporate the code yourself. I might do another post later but the web has many articles described this already, you should be able to find a set of good instructions.
Arthur
Related Posts: